
It’s safe to say that recommendation systems have become embedded in our online journeys and now guide a huge number of our daily decisions. From a business perspective, superior recommendation algorithms have been pivotal in driving success across all industries, from e-commerce to streaming to MarTech.
Recommendation systems (also known as recommender systems) collect and analyse large sets of user data using machine learning algorithms to suggest relevant items to users. The items can be a song, a movie, a product, or anything else, depending on the industry.
Recommender systems have evolved to become highly accurate and broadly applicable, meaning that they are now a proven way to generate enormous revenue for businesses. This compelling fact encourages more companies to adopt these systems to drive engagement and conversions.

Hello, I’m Alexandr Azizyan, Head of Data Science at VeliTech, where we specialize in creating innovative gaming products that drive engagement, increase revenue and deliver the best possible experience for players. Our company promotes a dynamic technologies-oriented environment, from cloud computing and microservices to data-driven solutions and Machine Learning, which gives technology enthusiasts like me plenty of opportunities to explore and experiment.
As a strong advocate of data science, I’m always excited to share insights into the complexity of recommendation systems. In this article, we’ll discover the incredible power of recommendation systems and how to leverage them to increase productivity and your bottom line. In addition, we’ll explore the critical challenges associated with building and implementing these systems and get valuable insights and solutions.
Let’s start with some technical basics.
Types of recommendation systems and how they work
Two main types of recommender systems serve as a foundation for all other methods: collaborative filtering and content-based filtering. Within these categories, some methods are more complex than others but remember: complexity doesn’t always bring the most accurate results. Ultimately, the best method for a particular business case depends on the volume and quality of the data you can collect and process.
Content-based filtering
Content-based filtering is about creating a profile for each user or item that truly captures its essence. Let’s take a movie recommendation system as an example. A movie profile will cover things like genres, actors, and popularity — these are the attributes that help us understand what makes a movie tick. On the user side, we can build a profile to include things like personal information, demographic data, or even their reviews and answers to certain questions.
But here’s the thing: content-based filtering requires gathering information from all sorts of different sources, which can be a bit tricky. It’s like trying to solve a puzzle with missing pieces.
Content-based filtering uses the characteristics and features of items to recommend other items similar to ones the user already likes, based on their previous actions or explicit feedback. It’s pretty straightforward to implement: we just need to extract all the item features, combine them into item embeddings, and measure the similarity of different item embeddings to find those that match the user’s preferences.
The idea here is to extract as much semantic information from the item as possible — such as text, images, audio, etc. — and embed it in vectors. We can do this using various machine learning and deep learning techniques as the first step of the recommendation.
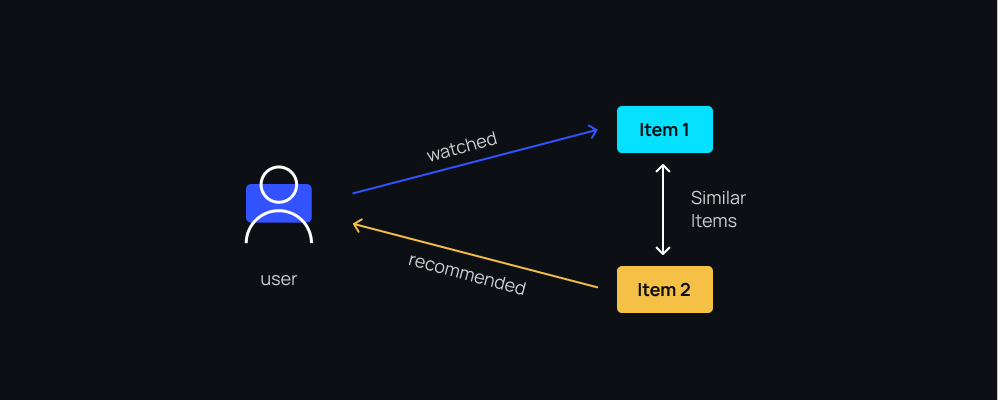
Collaborative filtering
In contrast to content-based filtering, collaborative filtering doesn’t rely on creating detailed profiles but instead looks at past user behavior (such as previous transactions or item ratings) to make recommendations.
Collaborative filtering examines the relationships between users and the connections between different products. By doing so, it can discover new associations between users and items that might not have been obvious before. It’s like uncovering hidden connections and saying, “Hey, you might like this because people similar to you also enjoyed it.”
Collaborative filtering is pretty versatile because it doesn’t depend on specific domains. It can handle those tricky data aspects that are hard to capture with content filtering alone. It’s a more accurate approach overall, but there’s a catch: collaborative filtering struggles with what’s known as the “cold start” problem. In other words, when there are new users or items that haven’t been previously rated or interacted with, collaborative filtering can’t really handle them well. In this situation, content-based filtering has the upper hand.
Once the cold start has passed and there’s enough aggregated data, the system predicts user preferences based on recorded patterns and similarities. As such, collaborative filtering is perfect for systems where users have many interactions with items.
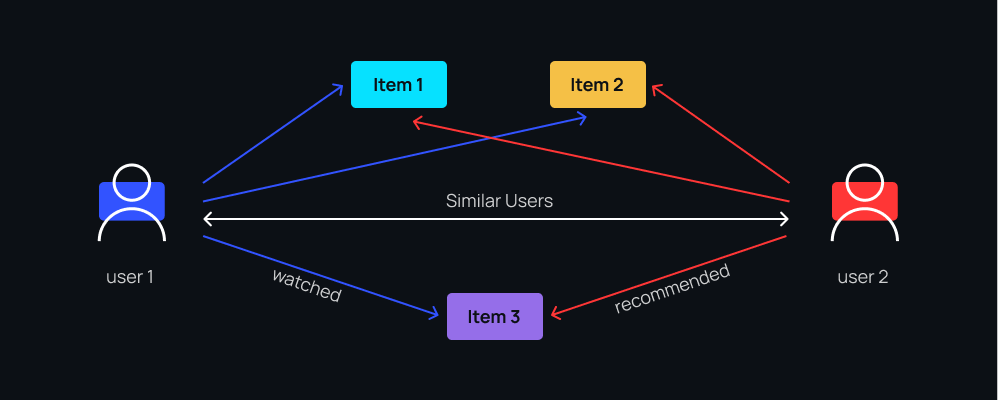
The figure below shows how collaborative filtering works. If two users have interacted with two items in a similar way (e.g., by viewing, liking, or purchasing them) and one of the users has viewed a third item, the system will recommend this item to the other user as well.
Matrix factorization
When it comes to collaborative filtering, there are two main areas we can delve into: neighborhood methods and latent factor models.
Neighborhood methods are all about finding connections between items or users. This is like mapping out a neighborhood of items or users to see who’s related to whom.
On the other hand, there are latent factor models, which aim to explain ratings by considering multiple factors we infer from rating patterns. These factors help us understand the underlying characteristics of both items and users.
Some of the most successful implementations of latent factor models come from matrix factorization, which made its debut during the Netflix Prize challenge. The idea is pretty simple: we use matrices to break down both items and users into vectors of factors. These factors are cleverly inferred from patterns in item ratings.
And here’s where it gets exciting: when those item and user factors show a strong correlation, we’ve got a recommendation!
Matrix factorization has gained a lot of popularity in recent years, and for good reason. It’s not just scalable and accurate when it comes to making predictions — it also offers a ton of flexibility for modeling all sorts of real-world situations.
The most valuable data for recommender systems is explicit feedback — when users provide direct input about their product preferences. The problem is that explicit feedback is often sparse because users only rate a small fraction of the available items, and this is where matrix factorization helps.
Matrices allow us to incorporate additional information and work around missing pieces. If explicit feedback is not readily available, we can rely on implicit feedback, i.e., by inferring user preferences from observed behavior. The result is a densely filled matrix of insights.
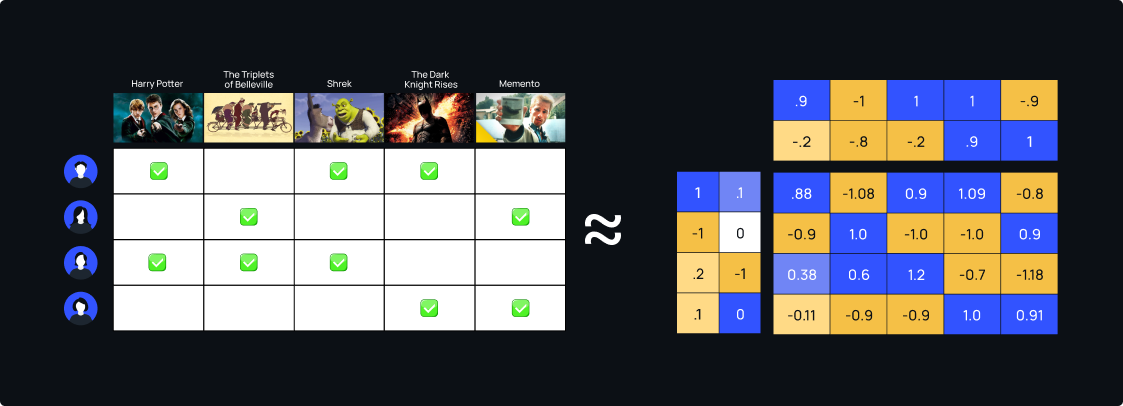
Matrix factorization models take users and items and map them into a joint latent factor space with high dimensionality so that user-item interactions are modeled as inner products in this space.
The main goal of matrix factorization is to break down a user-item matrix into two matrices with low ranks: the user-factor matrix and the item-factor matrix. These matrices work together to predict new items that users might find interesting.
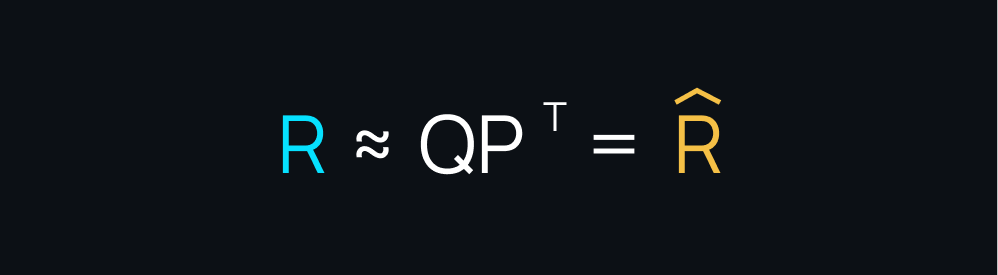
The beauty of matrix factorization lies in constructing a low-rank approximation of the user rating matrix. This approximation has a significant impact on the recommendations we give to users. It’s like distilling all the complex ratings into a simpler form that still captures the essence of what users like.
So how does matrix factorization work? When it comes to implementation techniques, we have a whole range of options. The classic approach is singular value decomposition (SVD), but there is also non-negative matrix factorization (NMF) that focuses on positive components. We also have Bayesian probabilistic matrix factorization (BPMF), which introduces a probabilistic twist.
All these techniques are amazing tools for capturing the similarities between users and items. They help us uncover hidden connections and provide tailored recommendations that users will appreciate.
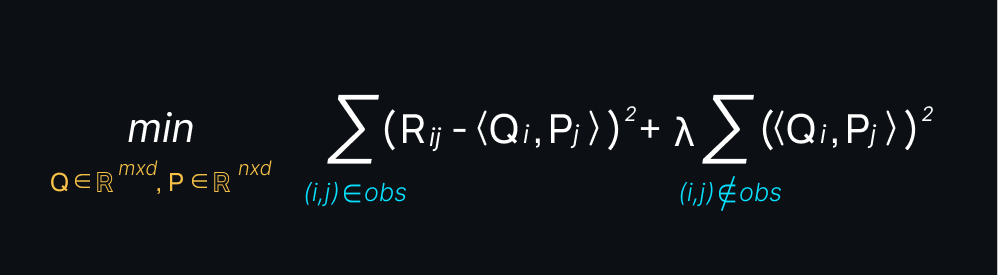
And here’s a tip: to minimise the objective function above, we can use methods like stochastic gradient descent (SGD) and alternating least squares (ALS).
The hybrid approach
As the name suggests, hybrid systems combine different methods to address the limitations of content-based and collaborative filtering by using all available data sources. This helps hybrid systems draw more accurate inferences and improve recommendations.
Still, this high performance comes at a price. Hybrid models are harder and more expensive to build and deploy, as they require large data sets, more computational resources, and specialised knowledge in deep learning and graph theory.
The two-tower model
One of the biggest challenges with matrix factorization — and its improved version, weighted alternating least squares (WALS) — is that it fails to incorporate data outside user-item interactions. Things like an item’s title and description, categories, language, user location, and search history are left out. This is where two-tower models come to the rescue.
Two-tower models are widely used and very effective. These are neural networks with two sub-models that learn separate representations for queries and candidates. In our case, these queries and candidates refer to users and items. The great thing about this is that the score for a given query-candidate pair is simply the dot product of the results from the two towers.
This architecture is also very flexible. In addition to user and item IDs, you can feed in any information that carries semantic context, such as user profiles, titles, descriptions, and more. It’s all about capturing the essence of both users and items in a meaningful way. As a result, with two-tower models, we can go beyond the basics and gain a more comprehensive understanding of the interactions between users and items.
When we use just user IDs and item IDs, a simple two-tower model is quite similar to a typical matrix factorization model. It’s made up of three key components:
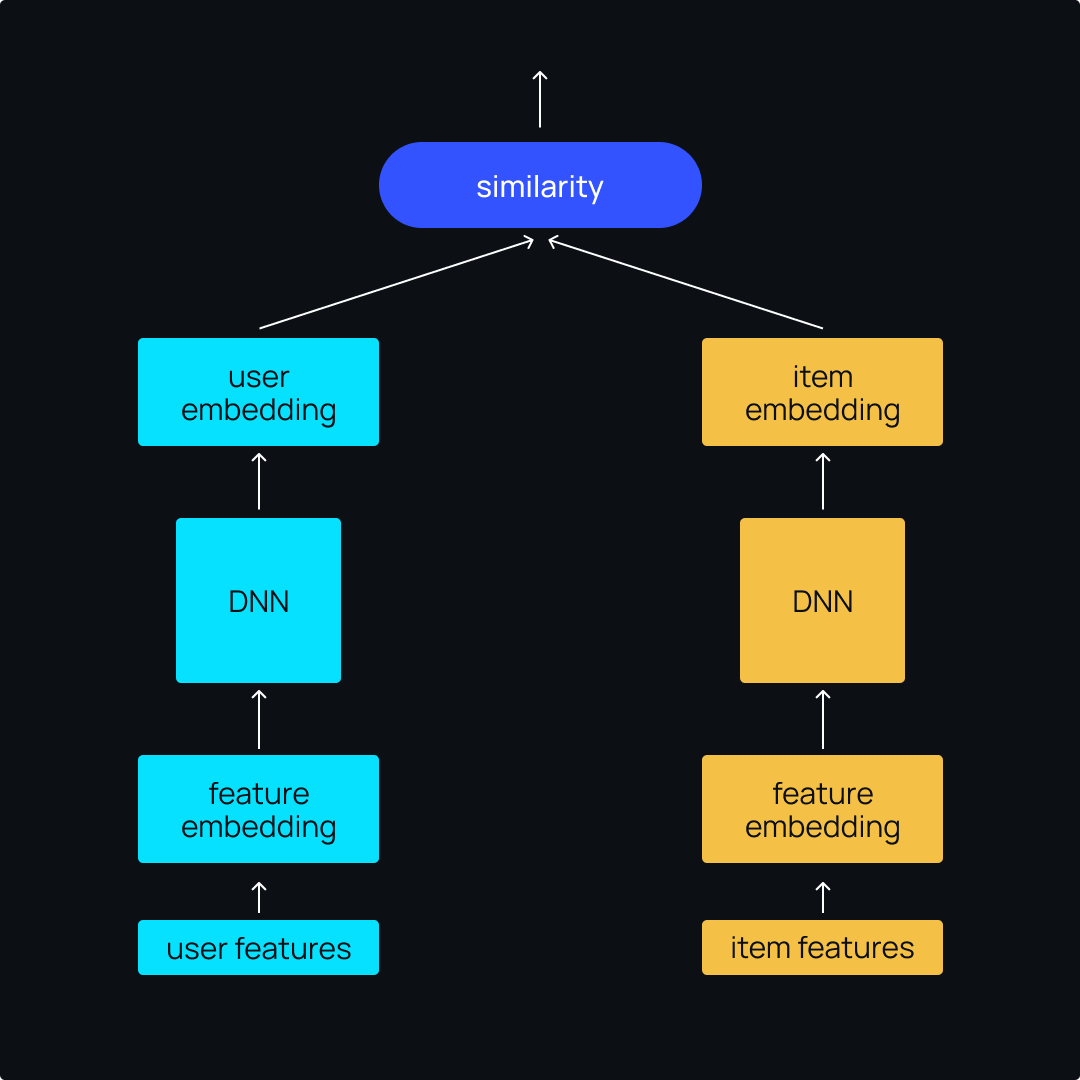
- The user tower takes user IDs and converts them into user embeddings. These embeddings are high-dimensional vector representations that capture the essence of each user.
- The item tower does the same thing but for item IDs. It transforms them into item embeddings, which are vector representations specific to each item.
- The loss function plays a crucial role in training the model. It aims to maximise the predicted affinity between users and items for interactions that happened while minimising it for interactions that didn’t happen.
To generate positive examples for the network to learn from (user-item pairs that we want the network to recommend), we look at the user’s past interactions. But there’s a challenge: if we only train the network with positive examples, it might just end up saying yes to every user-item pair, which will lead to poor recommendations. We need the network to learn to differentiate and demote poor recommendations too.
One common way to do this is with negative sampling, where we randomly select items the user hasn’t interacted with and treat them as negative examples. This way, the network learns to distinguish between positive and negative examples, ensuring that the recommendations it provides are meaningful and useful.
Graph neural networks
Graph-based models are becoming increasingly popular in many industries. In the context of recommendation systems, a graph is a structure consisting of a set of nodes that represent users and items and a set of edges that interconnect these nodes and signify their relationships.
Graph-based models have some major advantages. They provide better metrics and learn lightning-fast, even when we’re dealing with huge amounts of data. That’s because the representation of users and items is right there in the structure itself.
This means we can address the inherent graph structure between users and items or between products themselves. We can also add relations between entities by adding new types of nodes and edges. As a result, we don’t have to spend much time on feature engineering and extraction.
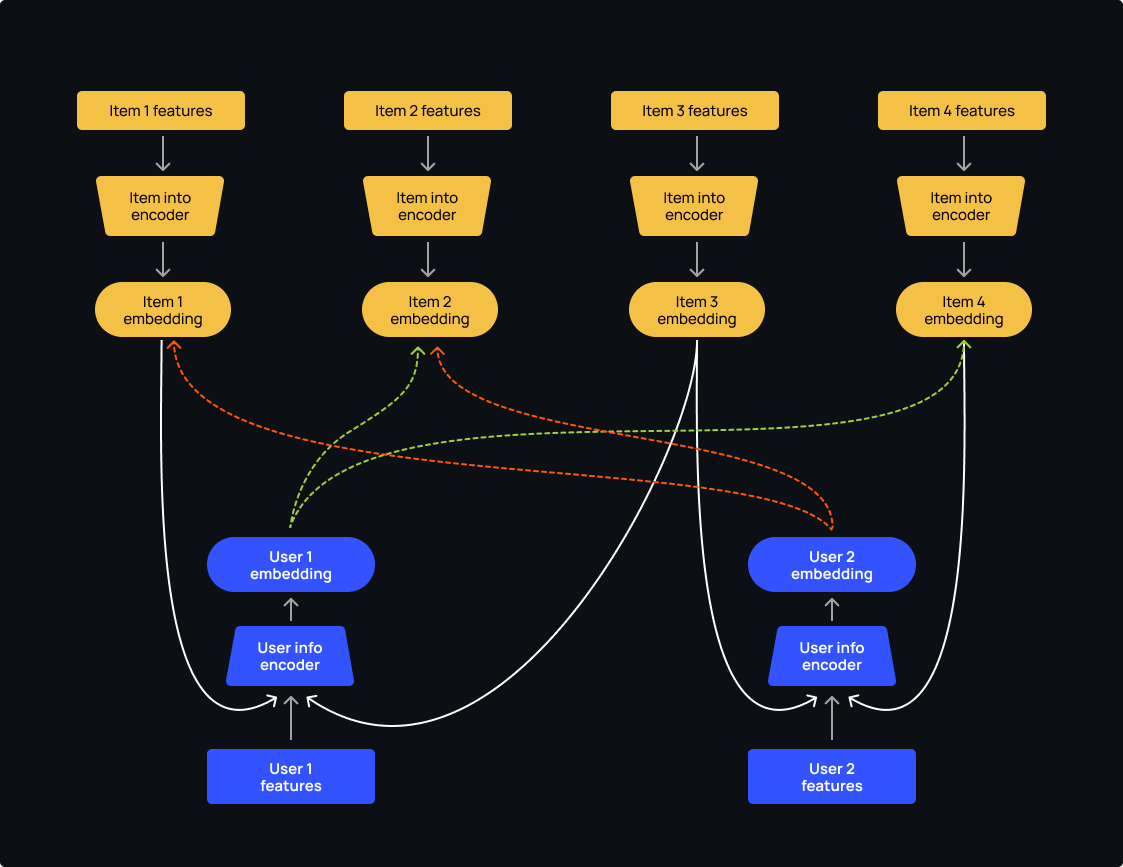
Graph neural networks (GNNs) can represent what a two-tower model can achieve. In fact, a two-tower model is essentially what a GNN model would look like if a graph had exactly two types of nodes and all the edges were between user and item nodes. That’s what we call a bipartite graph.
Graph convolutional networks (GCNs) use convolutional operations on the graph to aggregate information from neighboring nodes and update node representations. These updated representations can then be used to make recommendations.
Graph attention networks (GATs) use attention mechanisms to weigh the contributions of neighboring nodes when updating node representations. GATs have been shown to outperform GCNs in certain recommendation scenarios.
Temporal graph networks (TGNs) typically model the user-item interaction graph as a time-varying graph, where the nodes represent users and items, and the edges represent the interactions between them at different points in time.
Session-based recommendation systems
This new type of system offers real-time recommendations based on a user’s current session, behavior, and contextual information (device, location, etc.) instead of historical data and user profiles.
When it comes to next event prediction (NEP), there are many baseline methods to choose from. More recently, deep learning approaches have been making waves. Variants of graph neural networks and recurrent neural networks have been applied to tackle this task and show great potential. In fact, they currently hold the title of state-of-the-art approaches in NEP.
However, there’s another option worth considering: one that lies between simple heuristics and deep learning algorithms. It’s a model that can capture semantic complexity, and it does so with a single layer. Enter Word2Vec.
The Word2Vec method can be applied to problems involving sequences where the order is important. That’s because Word2Vec is designed to capture the relationship between words in a sequence. In the case of modeling a user’s browsing history, the history is ordered by time and likely contains valuable information about the user’s interests. Therefore, it makes sense to treat this problem as a sequential problem and apply Word2Vec to capture the user’s interests as they navigate through various products.
The most popular framework for building such models is Transformers4Rec.
Now that we’ve seen how these models function, let’s turn to some real-world applications.
Real-world examples of recommendation systems
Let’s look at how different recommender systems can be applied to deliver real-world results.
Spotify
It’s fair to say that Spotify’s powerful recommender algorithm has played a decisive role in driving its success as the leading music streaming service.
Spotify’s algorithm uses a mixture of graph-based models and reinforced learning to adjust suggestions in real time and create unique music journeys for users for the next week or month.

Here’s what the Spotify algorithm is built on:
- Content-based filtering. This includes analysing artist-sourced metadata (title, genre, artist name, etc.), raw audio signals (energy, danceability, and valence), and text with Natural Language Processing (lyrics, web content, and user-generated playlists).
- Collaborative filtering. This includes capturing user signals by studying playlists and listening session co-occurrence.

Amazon
Retail giant Amazon uses powerful hybrid systems to collect general data about products and customers along with data about the relationship and dependencies between them. The Amazon algorithm uses collaborative filtering to suggest products based on the purchase and browsing behaviour of other customers with similar interests, as well as product attributes, reviews, and ratings.
Netflix
Netflix is another pioneer in the recommender systems space, and the company pretty much owes its success to its algorithm. With massive volumes of data and computation power at its disposal, Netflix leverages hybrid models to analyse the watch and search patterns of similar users. It also uses the characteristics of movies and TV shows the user has watched and rated.

Fun fact: a few years back, Netflix organised a challenge with a $1 million prize for the winner who could develop a more accurate recommendation algorithm than their own.

TikTok
TikTok’s algorithm is also one of the main drivers of the platform’s prominence.
The algorithm is famous for its virality, diversity, and timeliness of recommendations. Like most tech giants with enormous volumes of data, TikTok’s recommender is run on hybrid systems, with a particular emphasis on consumption flow.
Google Maps
Google’s Maps platform uses shopping, visiting, and eating history to create a score for each user that determines whether a given place will suit their tastes.
These are just a few of the examples out there, but you don’t have to be a global giant to get the most out of recommendation algorithms.

Let’s look at how you can drive loyalty and conversions by implementing recommendation systems in your own omnichannel marketing.
Using recommendation systems in engagement & automation platforms
Omnichannel marketing tools help you connect with your customers through their preferred channels, such as email, social media, text, and mobile apps. They help your brand create a presence in your customers’ lives, thus driving awareness, customer engagement, and, ultimately, sales.
Amazon, for example, uses personalised emails and display ads across its partner networks to reach its customers with relevant off-platform recommendations. This allows them to nudge customers in the right direction across multiple channels and increases their chances of landing a purchase.
Using RecSys in omnichannel marketing tools allows you to address each potential customer as an individual, using their behaviour to personalise your channels, messaging, and offers. Instead of bombarding them with ineffective generic messaging, you show customers that you understand their needs and care about meeting them.
EDGE – our dynamic client engagement & marketing automation tool – is a great example of how RecSys can transform omnichannel marketing. With EDGE, you can
- Maximise your sales potential with RFM segmentation. By harnessing the power of customer behavior, the platform helps to identify and target micro-segments for optimal campaign performance and continuous validation.
- Transform your marketing strategy with AI-powered personalisation. Engage customers with omnichannel campaigns tailored to their unique interests.
Ultimately, it’s about predicting user behavior and creating personalised targeting to increase engagement, satisfaction, and sales.
The business advantages of recommendation systems

The decision to implement recommendation systems can seem like a big commitment that requires serious investment and must pay off. Yet in Twilio’s State of Personalisation 2021 report, 75% of business leaders said that personalisation is table stakes for digital experiences. What business ROIs are they pursuing? Let’s see.
Enhanced user satisfaction and engagement

According to Salesforce, 66% of customers expect brands to understand their needs. Buyers get unparalleled satisfaction from receiving relevant messages or discovering relevant items without having to do the legwork. Providing such a service shows you care about your users and understand their needs — and when people feel this way, they always come back for more.
Increased revenue and retention

In e-commerce, where effective cross- and up-selling accounts for a large chunk of revenue, accurate recommendations inevitably result in higher retention and conversions. 78% of consumers say they are more likely to make repeat purchases from companies that personalise their recommendations, according to McKinsey.
It’s no different for subscription-based platforms: the more relevant and engaging the content, the more likely users are to stay with or upgrade their subscription.
Better customer insights
Personalised recommendation systems give businesses valuable data on user preferences and behaviours. This insight is critical to informing your product development, marketing, and other business decisions.
Competitive edge
Today, accurate and relevant recommendations have become a strong competitive differentiator in almost any business that involves consumption or discovery. Take any company in these areas that has made it to the top, and you’ll see superior predictive analytics systems in place.
Challenges in building recommendation systems

There are several challenges to building recommendation systems. The main ones are related to data acquisition and processing, the technical work of modeling and deployment, and ethical components regarding privacy and bias. Let’s look at them in more detail.
The cold-start problem
As we’ve already seen, the cold-start problem is the infamous downside of collaborative filtering systems. A cold start occurs when there is insufficient historical data on user-item relationships. As this data forms the basis of suggestions in collaborative filtering, the recommendation system is unable to make accurate predictions or recommendations for new users, items, or systems.
Data sparsity
A data sparsity problem occurs when a user only interacts with a small subset of the available items or content. This behaviour makes it difficult for the algorithm to predict which items or content might interest the user. For example, a user who views and purchases only two out of 2,000 items generates low coverage, which leads to a sparse dataset.
The problem of data sparsity is challenging, as it can occur in all types of systems. Different techniques to tackle it include a combination of matrix factorisation, neighborhood-based methods, deep learning, and other approaches.
Overfitting
Overfitting is when a user ends up in a loop of items similar to those they have interacted with before, leading to a lack of diversity and bias. This problem occurs when a model knows too much about certain user-item interactions, which makes it too specific to the training data and unable to generalise the data to new users or items.
To prevent the model from learning too much from the same type of thinking, we use various regularisation techniques such as parameter tuning, model, and event data sampling.
Scalability
As a system grows, the computing power required to make accurate and timely recommendations can skyrocket, which increases the system’s cost. When algorithms aren’t built with scalability in mind, the transition to large-scale systems becomes a problem. This is particularly true for collaborative filtering systems, where the resources required for generating new recommendations increase significantly for large datasets.
To fix the scalability problem, you must have enough computational power and a mathematically scalable algorithm. If you use distributive computing to calculate your equations, you should always be able to aggregate them.
Data privacy
The introduction of data protection regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) has seriously limited the amount of specific data that algorithms can use.
There are two main ways to address this problem:
- Working with encrypted user data
- Using differential privacy by adding random noise to blur a user’s personal information or browsing history
Real-world testing
In-house models suffer from a lack of real-world user feedback, which means they can turn out to be flawed in practice, no matter how powerful they are. This is why it’s imperative to do A/B testing and have separate models running in production with traffic split between them. With this approach, you can use observed user activity to decide whether the model needs to be improved and track how user behavior changes over time.
Among other things, the problem of simulating real-world performance has forced data scientists to shift from a model-centric to a data-centric approach. Instead of developing superior models to ensure accurate predictions, data scientists now focus more on gathering high-quality data, which gives the same results with less advanced or demanding models.
There are many other challenges and different solutions, but let’s save this conversation for another time. Instead, let’s look at the trends that are shaping recommendation engines today and what they mean for businesses.
The future of recommendation systems
The world of AI is evolving at a fast pace, and recommender algorithms are following suit. The future of recommendation engines in marketing and beyond is likely to be shaped by the following technological trends and advances:

Integration with other technologies. Recommendation systems are becoming increasingly integrated with marketing tools for CRM, marketing automation, and analytics to create more effective marketing strategies. With the expansion of IoT and smart environments, suggestion systems will become more embedded in different areas of our lives. From smart homes and car controls to connected cars, recommendation systems will use real-time data to deliver personalised suggestions that improve our user experience.

An increased focus on privacy. As concerns about data privacy continue to grow, companies need to ensure that their recommendation engines are transparent and ethical in how they collect and use data. This could involve encrypting user data, using differential privacy methods, or developing new recommendation algorithms that don’t rely on personal data.

More focus on contextual, real-time recommendations. With the increase in customer touchpoints and data, there is a trend toward real-time recommendations based on a user’s current context and behavior. As a result, contextual recommendations will likely play an important role in future recommendation processes and take into account factors like user location, time of day, and even mood.

The rise of multi-model systems. In the future, recommendation systems will become multi-model, meaning that they will span multiple formats and data types such as text, images, audio, and video. This will help us better understand what users want and provide more relevant recommendations.
Increased transparency. As recommendation systems grow more complex, users will want to know the rationale behind some recommendations, and businesses will need to ensure that their policies are transparent and fair. This will lead to the development of more interpretable AI — systems with a more transparent, meaningful, and efficient decision-making process — and new methods and tools that will make this possible.

Personalisation at scale. As the amount of data grows, recommendation models will need to become more powerful to effectively process it and give timely and accurate recommendations. This tendency will also likely involve developing new algorithms using less data to make predictions.
Conclusion
The power of personalisation is no longer reserved for the elite few like Amazon or YouTube. More and more businesses across the board are investing in the development of recommender systems to power up their marketing, improve customer experience, and drive their bottom line — and this trend will only accelerate.
With the rise of data-centricity, recommendation systems have become embedded not only in how we do things on the internet but in how we run business, too. Long gone are the days when we had to rely on biased and flawed empirical knowledge to dictate our next steps. Now, we can use accurate insights gathered from our own users to inform our most important business decisions.
Of course, implementing recommender systems isn’t without its challenges. Setting up an effective system requires deep expertise in data science and can be resource-intensive. To ensure optimal results, you need to consider your business needs and the resources available before you choose and deploy the system.
But one thing is certain: companies that can implement effective recommender systems and deliver personalised, relevant recommendations to their customers will be set up for success for years to come.


